
Spanner is Google’s new DBaaS offering. Google touts it as having the best features of both a relational database and a document or NoSQL database. So, why did Google create Spanner? Google needed:
- Horizontally scale
- ACID transactions
- No downtime
- Automatic sharding
- Seamless replication
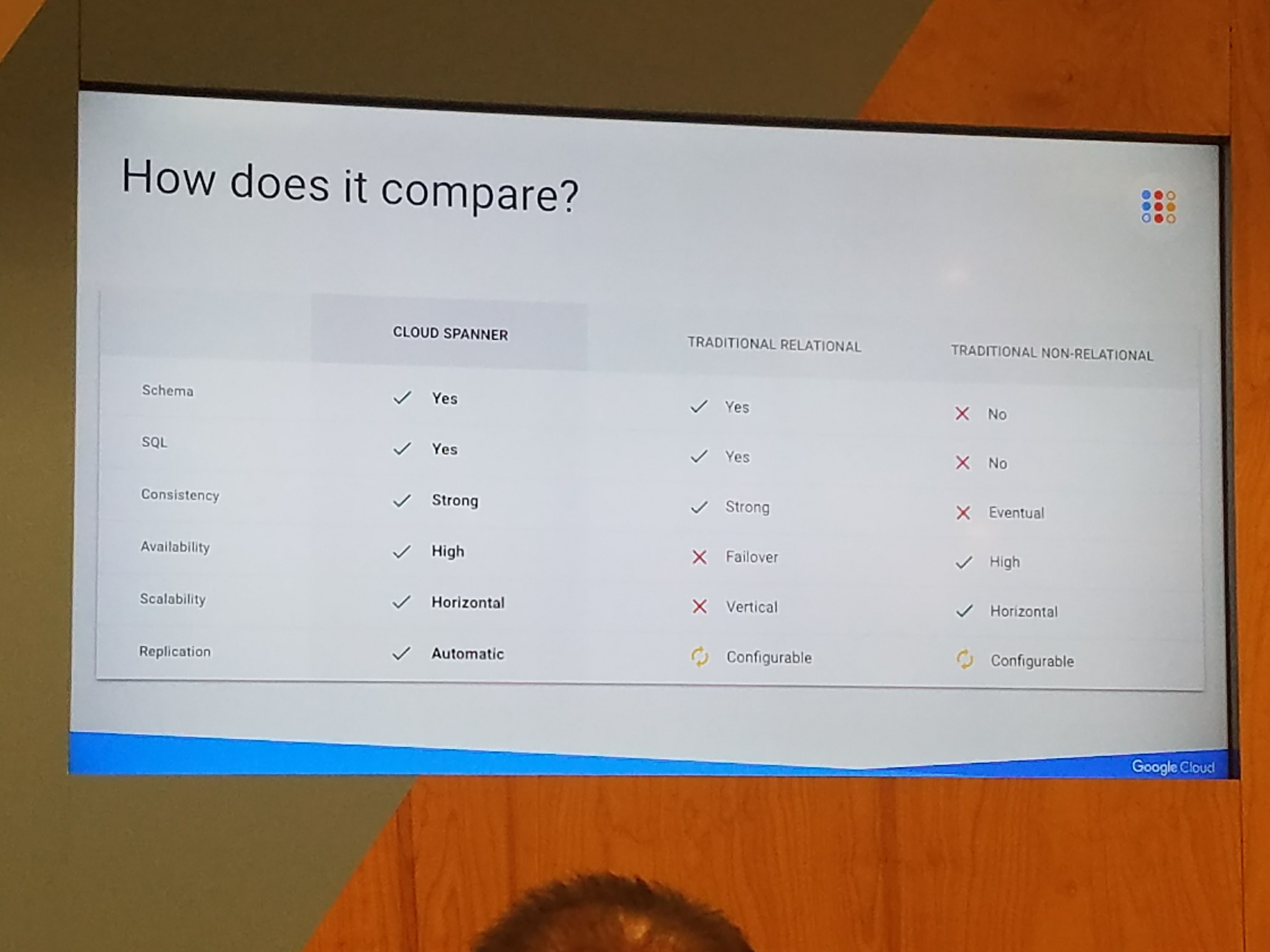
Cloud Spanner is Google’s mission-critical relational database service. It was originally built to run Google Adwords internally, but is now exposed as a public service. It is a multi-regional database and can span millions of nodes.
Open Standards
- Standard SQL (ANSI 2011)
- Encryption, Audit logging, IAM
- Client libraries (Java, Python, Go, Node.js)
- JDBC driver
Architecture
Spanner is provisioned in instances. The instances exist in different zones. This architecture allows for high availability. The customer can choose which regions the database instances are placed in. Writes to the database are synchronous and are replicated across nodes.
Spanner supports an interleave data layout. This specifies that data should be written in close proximity on disk. The result is much better read performance. Spanner is designed for large amounts of data. It is not as efficient for small data sets.
